Lors du téléchargement de données à partir de Donneesclimatiques.ca, les utilisateurs peuvent avoir l’option de télécharger des fichiers dans un format appelé « netCDF ». Pour ceux qui n’ont pas l’habitude de travailler avec des données climatiques, ce format de fichier n’est pas forcément familier. Cet article donne un aperçu des fichiers netCDF, en expliquant leur structure, les raisons pour lesquelles ils sont largement utilisés, et en donnant des conseils sur la façon de les ouvrir et de les lire.
Qu'est-ce qu'un fichier netCDF ?
Contrairement à une feuille de calcul classique qui ne comporte que deux dimensions, les lignes et les colonnes, un fichier Network Common Data Form, ou netCDF peut stocker des données dans un nombre illimité de dimensions spatiales et temporelles. Ces fichiers contiennent également d’autres informations sur les données, comme les unités et les informations sur les droits d’auteurs. Les utilisateurs reconnaissent un fichier netCDF à son extension « .nc ». Chaque jour, de plus en plus de données climatiques sont partagées en format netCDF en raison de sa flexibilité et de sa normalisation.
Comprendre la puissance des fichiers netCDF
Les fichiers netCDF sont couramment utilisés pour stocker et accéder à des données multidimensionnelles en grille. Imaginez la Terre enveloppée d’un fin maillage, créant des milliers de petites boîtes à sa surface appelées points de grille. Chaque point de grille représente une zone spécifique, généralement définie par la latitude et la longitude. Les valeurs d’un fichier netCDF indiquent une mesure climatique spécifique, telle que la température ou les précipitations, pour chaque cellule de la grille et à un intervalle de temps spécifique (quotidien, mensuel ou annuel).
Comme pour une miche de pain, il est possible d’écrire un programme informatique qui extrait une « tranche » de données sur une dimension spatio-temporelle spécifique dans un fichier netCDF afin d’examiner comment des variables telles que la température ou les précipitations évoluent dans le temps et dans l’espace. Cette tranche de données peut ensuite être cartographiée (une seule tranche de temps sur une vaste zone) ou représentée sur un graphique de séries temporelles (une tranche pour un seul emplacement durant un intervalle de temps). Le format de fichier netCDF permet ces deux types d’analyses.
Structure et composantes d'un fichier netCDF
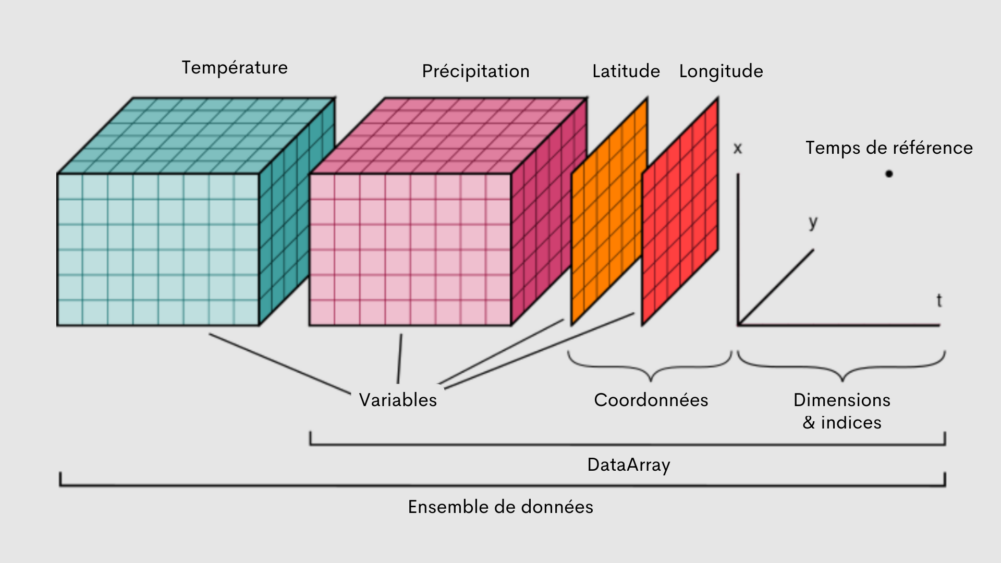
La figure 1 présente les principales composantes d’un fichier netCDF. Le Dataset contient plusieurs DataArrays, qui contiennent les données réelles, telles que des variables comme la température et les précipitations. Ces variables sont structurées selon des coordonnées – dans ce cas, la latitude et la longitude – et cartographiées sur différentes dimensions (par exemple, x, y et t pour le temps). Les dimensions représentent les axes des données (spatiales et temporelles) et les index fournissent des points de référence dans ces dimensions. Cette structure permet de stocker et d’accéder efficacement à de grands ensembles de données climatiques multidimensionnelles. Chacune de ces composantes est examinée plus en détail ci-dessous.
Figure 1. Visualisation des composantes d'un fichier netCDF. Source : Structures de données (xarray.dev).
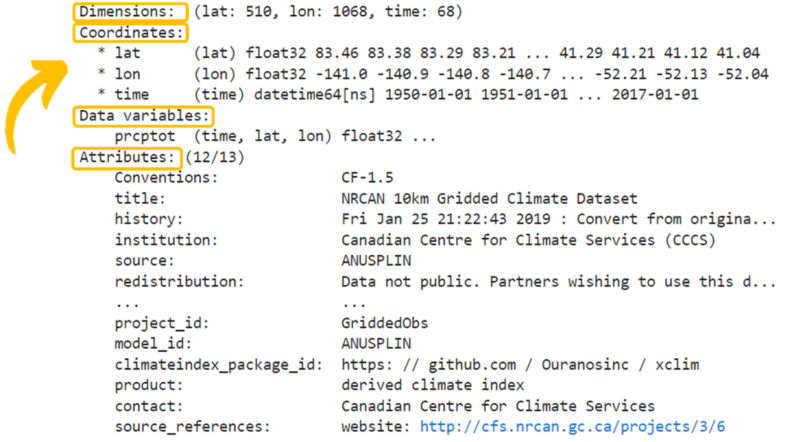
- Dimensions/index : Les dimensions (ou index) d’un jeu de données déterminent sa taille et sa structure (par exemple, le nombre de points de longitude/latitude et le nombre de pas de temps). Les dimensions les plus courantes dans les fichiers netCDF contenant des données climatiques sont la latitude, la longitude et le temps, mais certains ensembles de données comprennent d’autres paramètres tels que l’altitude. Par exemple, la figure 2 montre les dimensions d’un fichier netCDF de NRCANMET. Les dimensions de ce fichier de données sont 510 pas de lat (latitude), 1068 pas de lon (longitude) et 68 pas de temps.
- Coordonnées (Coordinates): Les coordonnées des données indiquent l’emplacement exact de chaque point de grille le long de chaque dimension (par exemple, heure spécifique, latitude, longitude). Dans la figure 2, vous pouvez voir des listes de valeurs associées à chaque dimension (lat, lon, time). Cela nous montre que le fichier couvre les latitudes de 83.46 à 41.04, les longitudes de -141.0 à -52.04, et les périodes mensuelles de janvier 1950 à janvier 2017.
- Attributs (Attributes): Les détails concernant le jeu de données sont stockés dans les attributs qui comprennent souvent une description de base du jeu de données, comme le(s) modèle(s) utilisé(s) pour produire les données et la date de production. Les attributs du fichier NRCANMET de la figure 2 comprennent des informations tels que le titre (title), la date de création ou de mise à jour du fichier (history) et les références des données (source_references).
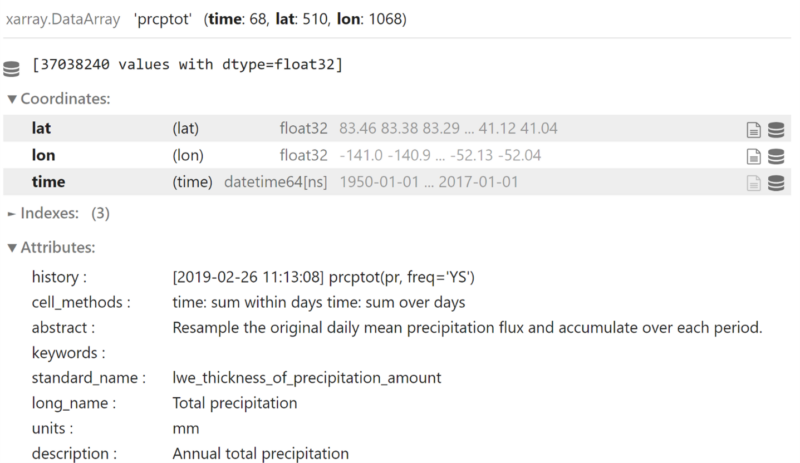
- Variables de données (Data variables): C’est là que sont stockées les données climatiques. Chaque variable est située dans la même structure que les dimensions. Par exemple, dans le fichier de la figure 2, il y a une variable de données appelée prcptot, représentant les précipitations totales, où chaque valeur est associée à une latitude, une longitude et une dimension temporelle. Un fichier netCDF peut contenir de nombreuses variables, et chaque variable doit également avoir ses propres attributs, comprenant généralement un nom plus long et plus descriptif pour la variable et des informations sur ses unités.
Figure 2. Description des composantes d'un fichier netCDF de précipitations NRCANMET.
Pourquoi les fichiers netCDF sont-ils si largement utilisés pour les données climatiques ?
La capacité des fichiers netCDF à stocker de multiples variables n’est qu’une des raisons de leur popularité croissante. Plutôt que d’avoir besoin de fichiers séparés pour les métadonnées (informations sur les données stockées), les fichiers netCDF correctement formatés incluent des informations sur les attributs telles que les descriptions de données et les unités. Toutes les informations nécessaires sont ainsi contenues dans un seul fichier, ce qui facilite son utilisation et son partage.
Les fichiers netCDF sont généralement plus petits que d’autres formats qui stockent la même quantité de données, car ils sont bien compressés, ce qui permet d’économiser de l’espace de stockage et de faciliter le partage. L’une des principales raisons de cette efficacité est que les coordonnées, telles que les latitudes, les longitudes et les pas de temps, ne sont stockées qu’une seule fois dans le fichier, au lieu d’être répétés pour chaque point de données. Même si les fichiers netCDF peuvent être volumineux, la majeure partie de l’espace est occupée par les données climatiques proprement dites, contrairement à d’autres formats tels que les valeurs séparées par des virgules (CSV), où les métadonnées et les coordonnées occupent souvent plus d’espace. Pour en savoir plus sur les avantages des fichiers netCDF, consultez la fiche technique netCDF d’Unidata (disponible en anglais seulement).

Ouverture et lecture de fichiers netCDF
Le principal inconvénient des fichiers netCDF par rapport à d’autres formats de données (disponible en anglais seulement), tels que les CSV, est qu’ils ne peuvent pas être facilement ouverts dans des tableurs tels que Microsoft Excel sans installer de modules complémentaires. Les fichiers netCDF conviennent mieux aux environnements de programmation, tels que Python ou R. Cela dit, il existe certaines options pour ouvrir et visualiser le contenu d’un fichier netCDF sans avoir besoin d’apprendre un langage de programmation.
Panoply NetCDF Data Viewer de la NASA (disponible en anglais seulement) est un outil gratuit qui permet de visualiser les données netCDF. Dans Panoply, les utilisateurs peuvent générer des figures simples et visualiser différentes tranches de données. Une présentation de Panoply pour les débutants est disponible ici (en anglais uniquement). Notez que Panoply nécessite Java, qui est un logiciel payant lorsqu’il est utilisé à des fins commerciales (des substituts gratuits sont disponibles et peuvent être trouvés dans le fichier readme de Panoply). Pour une analyse simple, des plugiciels gratuits pour Microsoft Excel permettent d’ouvrir des fichiers netCDF, ou les données peuvent être importées sous forme de couche matricielle dans un logiciel SIG comme ArcGIS.
Pour ceux qui ont une certaine expérience de la programmation informatique, il existe plusieurs bibliothèques de codage qui rendent le travail avec les fichiers netCDF relativement simple. Un exemple est xarray, une bibliothèque netCDF pour les utilisateurs de Python. Des tutoriels détaillés et des exemples de manipulation de fichiers netCDF à l’aide de Python sont disponibles sur la page des tutoriels PAVICS, la bibliothèque Pangeo et la page des tutoriels et vidéos de xarray (disponibles en anglais seulement).
PAVICS (Power Analytics and Visualization for Climate Science) est un environnement de programmation Jupyter notebook virtuel, basé sur python, avec xarray préinstallé. Les utilisateurs peuvent créer une connexion sur PAVICS en visitant le site mentionné ci-dessus.
Les blocs de code suivants montrent comment ouvrir et lire un fichier netCDF dans un environnement de programmation Python tel que PAVICS. Les utilisateurs à la recherche d’autres exemples devraient consulter le bref tutoriel sur PAVICS (disponible en anglais seulement).
# Charger le paquet xarray dans python
import xarray as xr
# Spécifiez l'emplacement de votre fichier de données netCDF
path = "path/to/file.nc"
# Importation du fichier
ds = xr.open_dataset(path)
Remarque : les fichiers netCDF peuvent être plus longs à ouvrir que d’autres types de fichiers, tels que les fichiers CSV.
La commande suivante permet d’imprimer une liste détaillée des composantes du fichier netCDF (les mêmes composantes que celles décrites dans la figure 2) :
Voici quelques commandes supplémentaires que les utilisateurs peuvent utiliser pour visualiser des éléments spécifiques du fichier :
- Consulter la liste des attributs du jeu de données : attrs
- Consulter les coordonnées du jeu de données : coords
- Consulter une liste de variables de données (avec leurs attributs) : variables
- Pour une liste de noms de variables et de coordonnées (sans attributs) : list(ds.variables)
La commande suivante permet d’imprimer des informations sur une variable spécifique du fichier netCDF :
# Spécifier la variable d'intérêt
var = "prcptot" # précipitations totales dans NRCANMET
print(ds[var])
Tutoriel complet
Après avoir ouvert et visualisé le contenu d’un fichier netCDF, les utilisateurs voudront très probablement effectuer des analyses personnalisées supplémentaires (par exemple, calculer un indicateur personnalisé tel que le « nombre de jours par an supérieurs à 33 °C relatifs dans une région spécifique ») avant de créer des visualisations de données personnalisées (c.-à-d. des cartes, des graphiques et des tableaux).
Là encore, PAVICS contient plusieurs tutoriels intégrés qui montrent comment programmer ces types d’analyses et présentent des commandes de visualisation. Il n’entre pas dans le cadre de cet article d’expliquer comment développer ces types de programmes ; cependant, l’exemple de code suivant montre comment on peut aborder ce type d’analyse personnalisée.
Le bloc de code ci-dessous extrait et analyse les données climatiques d’un fichier netCDF pour une région spécifique, dans ce cas, le parc national de Terra Nova. Il commence par charger un fichier de formes (shapefile) qui contient les limites du parc et les reprojette dans un système de coordonnées géographiques standard. Le programme accède ensuite à un ensemble de données climatiques (en particulier les projections de températures maximales d’un modèle climatique mondial à échelle réduite) à partir d’une URL spécifiée et regroupe en sous-ensemble les données pour les faire correspondre aux limites géographiques du parc. À l’aide de la bibliothèque xclim, il calcule le nombre de jours par an où la température maximale dépasse 33°C. Le programme calcule ensuite deux types de moyennes : une moyenne spatiale des données sur l’ensemble du parc et une moyenne temporelle des données sur la période 2051-2080. Enfin, il visualise les données sur une carte géographique à l’aide d’un graphique en quadrillage, qui comprend une échelle de couleurs pour représenter les résultats et une carte de base pour le contexte géographique.
# Importer les bibliothèques nécessaires
from xclim import atmos # Calculs des indices climatiques
from clisops.core import subset # Sous-ensembles et autres opérations sur les jeux de données climatiques
import xarray as xr # Pour la manipulation et l'analyse de tableaux multidimensionnels (par exemple, les fichiers netCDF)
import geopandas as gpd # Pour travailler avec des données géospatiales
import pandas as pd # Manipulation et analyse des données
import matplotlib.pyplot as plt # Bibliothèque de traçage
import hvplot.xarray # Tracé de haut niveau pour les données xarray
# Définir le répertoire et charger le fichier de formes (shapefile) contenant les limites du parc
shp_file_dir = '/notebook_dir/writable-workspace/Training Session/input/' # Répertoire pour les fichiers shapefile
shp_file = gpd.GeoDataFrame.from_file(shp_file_dir + 'All_NP_Boundary.shp') # Charge le fichier shapefile dans un GeoDataFrame
# Spécifier le parc d'intérêt
park = 'Terra Nova NP'
# Définir l'URL de l'ensemble de données climatiques netCDF (projections de températures maximales à partir d'un modèle climatique spécifique)
url = 'https://pavics.ouranos.ca/twitcher/ows/proxy/thredds/dodsC/birdhouse/pcic/CanDCS-U6/CMIP6_BCCAQv2/UKESM1-0-LL/tasmax_day_BCCAQv2+ANUSPLIN300_UKESM1-0-LL_historical+ssp585_r1i1p1f2_gn_19500101-21001230.nc'
# Extraire le polygone du parc sélectionné et s'assurer qu'il est dans le bon système de référence de coordonnées (EPSG:4326 pour WGS84)
park_polygon = shp_file.loc[shp_file['Park_Name_'] == park].to_crs(epsg=4326)
# Réaliser un sous-ensemble du jeu de données climatiques pour correspondre à la forme du parc avec une petite zone tampon pour éviter les problèmes de limites.
extraction = subset.subset_shape(
xr.open_dataset(url),
shape=gpd.GeoDataFrame(geometry=park_polygon.buffer(0.05))
).drop_vars('crs') # Supprimer la variable CRS inutile
# Calculer le nombre de jours où la température maximale dépasse 33°C (indice tx_days_above) sur une base annuelle
threshold_extraction = atmos.tx_days_above(tasmax=extraction.tasmax, thresh='33 degC', freq='YS')
# Calculer la valeur moyenne par zone en latitude et en longitude pour toutes les années.
extraction_area_avg = subset.subset_time(threshold_extraction).mean(dim=['lat', 'lon'])
# Calculer la valeur moyenne dans le temps pour la période 2051 à 2080
extraction_time_avg = subset.subset_time(threshold_extraction, start_date='2051', end_date='2080').mean(dim='time')
# Créer un graphique en quadrillage pour les données moyennées sur la période de temps sélectionnée
quadmesh_plot = extraction_time_avg.hvplot.quadmesh(
'lon', 'lat', # Spécifier les dimensions de longitude et de latitude pour le tracé
geo=True, # Activer les coordonnées géographiques
cmap="Spectral_r", # Utiliser la carte de couleurs "Spectral_r" pour la visualisation
tiles="EsriImagery", # Ajouter la carte de base de l'imagerie Esri pour le contexte géographique
title='Exemple de graphique montrant le nombre projeté de jours supérieurs à 33C par année (2051 à 2080) pour un mode de climat spécifique' # Titre du graphique
)
# Afficher le graphique
quadmesh_plot
Trouver des fichiers netCDF sur Donneesclimatiques.ca
Les utilisateurs peuvent télécharger des fichiers netCDF pour des variables spécifiques qui les intéressent à partir de la page Téléchargement sur Donneesclimatiques.ca.